|
Ceyuan Yang PhD Student Department of Information Engineering The Chinese University of Hong Kong E-mail / Google Scholar / Github |

|
Full Publications [Home]
equal contribution +corresponding author

|
Exploring Sparse MoE in GANs for Text-conditioned Image Synthesis,
|
|
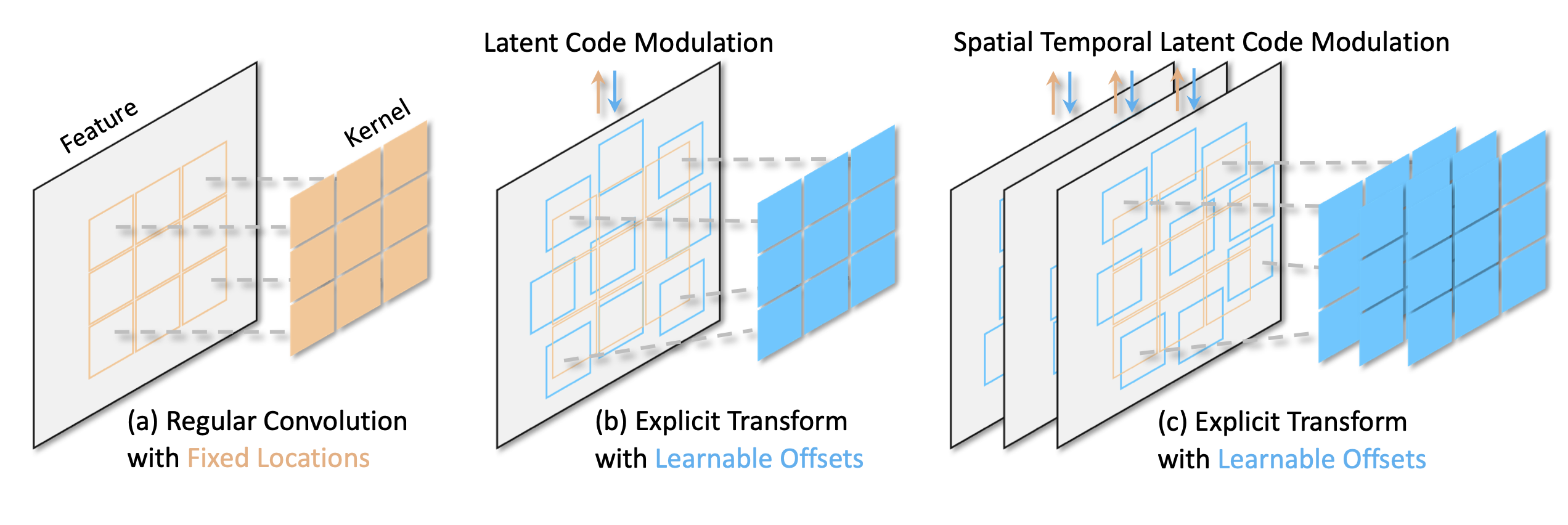
Learning Modulated Transformation in GANs,
|
|
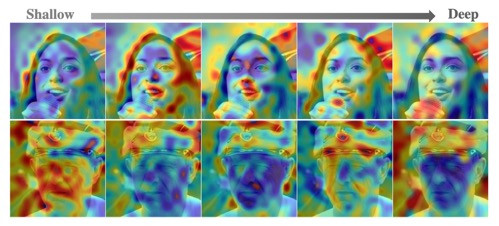
Revisiting the Evaluation of Image Synthesis with GANs,
|



|
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning,
|
|
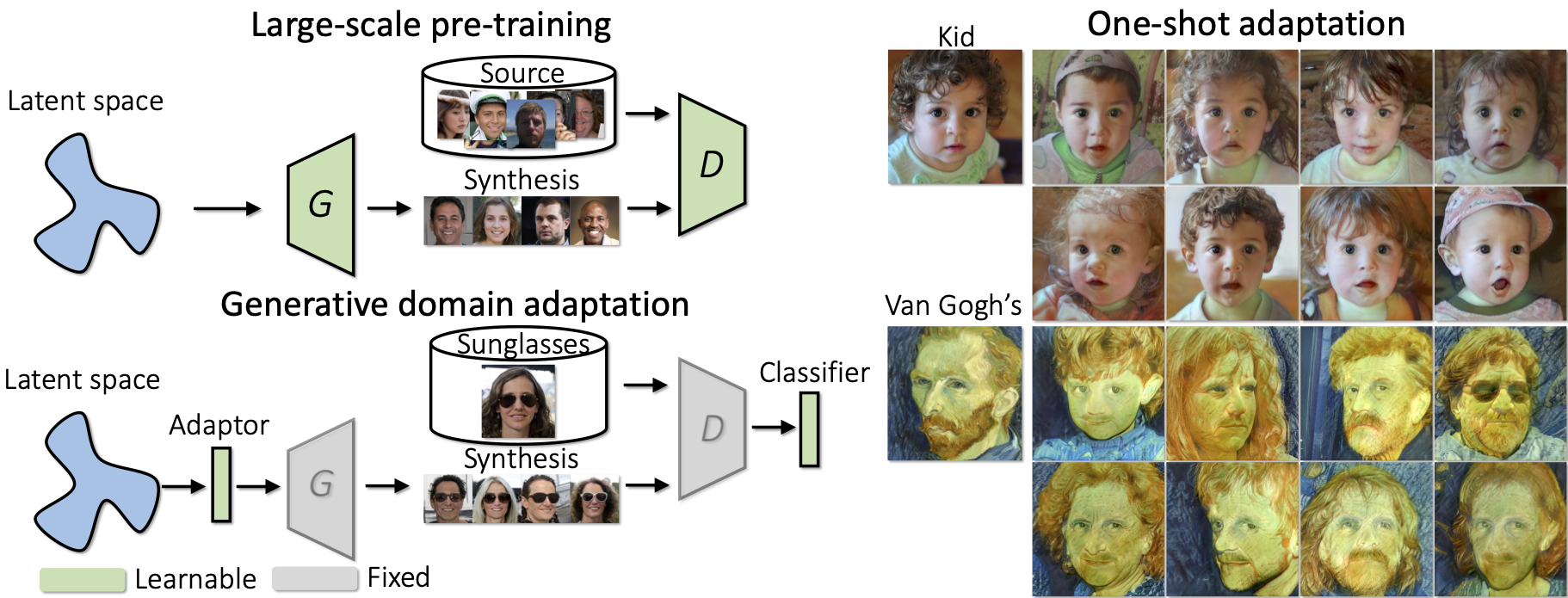
One-Shot Generative Domain Adaptation,
|
|
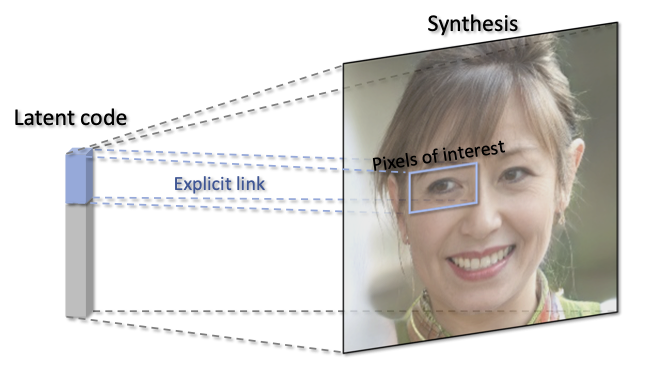
LinkGAN: Linking GAN Latents to Pixels for Controllable Image Synthesis,
|
|
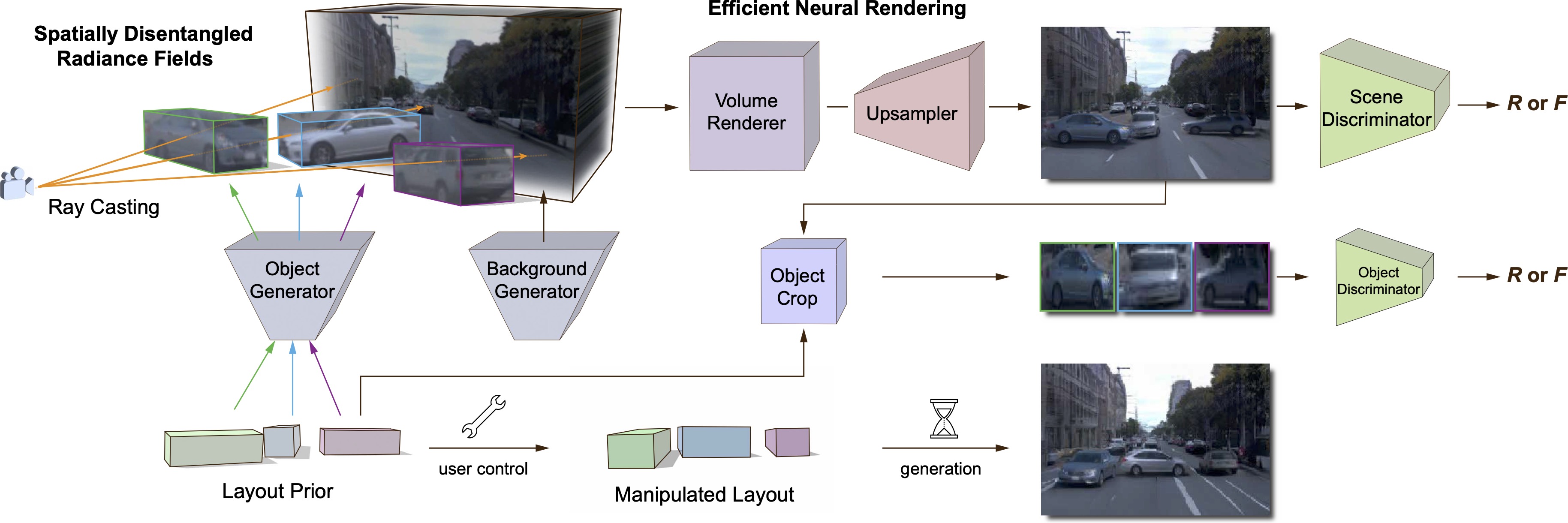
DiscoScene: Spatially Disentangled Generative Radiance Field for Controllable 3D-aware Scene Synthesis,
Highlight Presentation
|
|
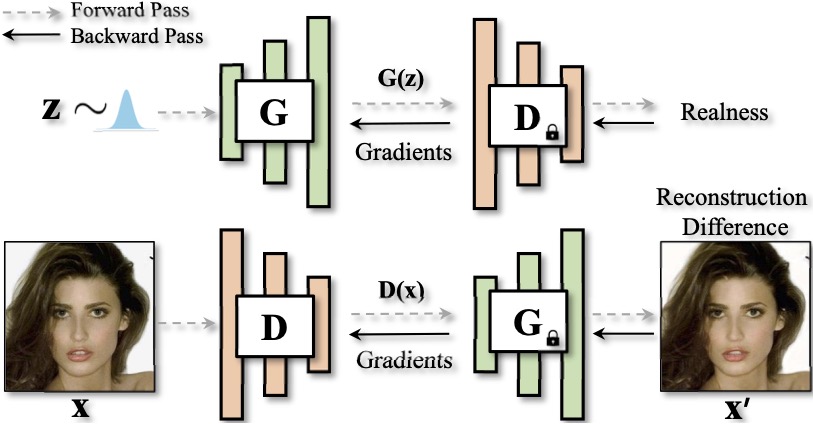
GLeaD: Improving GANs with A Generator-Leading Task,
|

|
Towards Smooth Video Composition,
|

|
Improving GANs with A Dynamic Discriminator,
|

|
Accelerating Diffusion Models via Early Stop of the Diffusion Process,
|
|
Prototypical Contrast Adaptation for Domain Adaptive Semantic Segmentation,
|
|
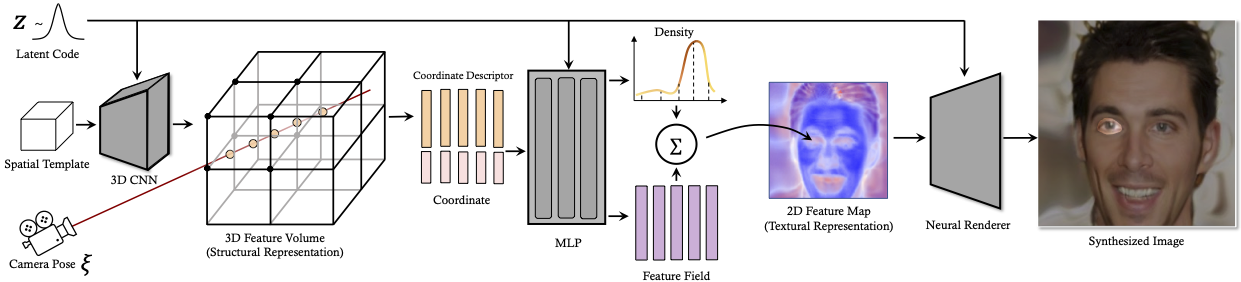
3D-aware Image Synthesis via Learning Structural and Textural Representations,
|
|
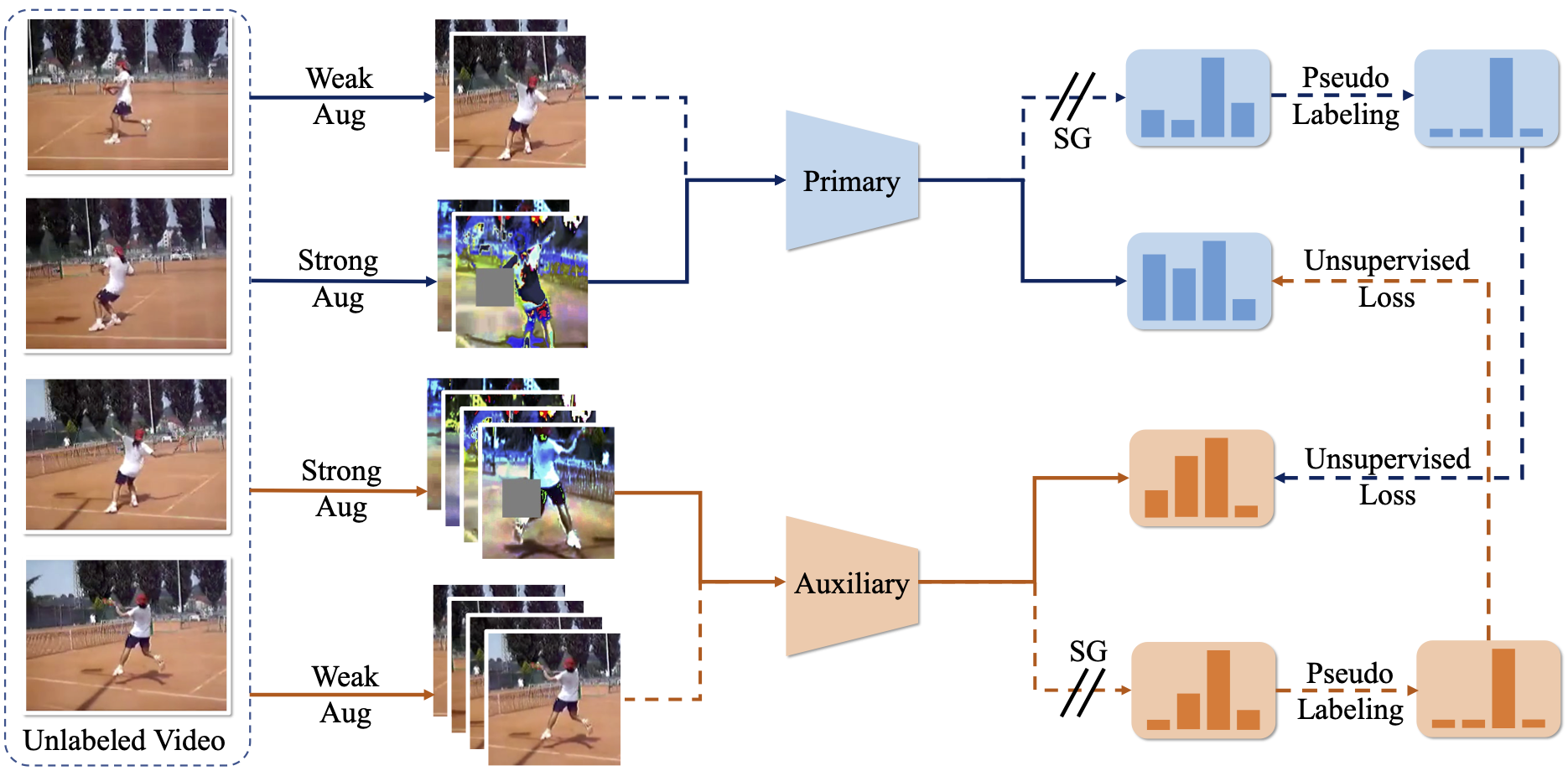
Cross-Model Pseudo-Labeling for Semi-Supervised Action Recognition,
Oral Presentation
|
|
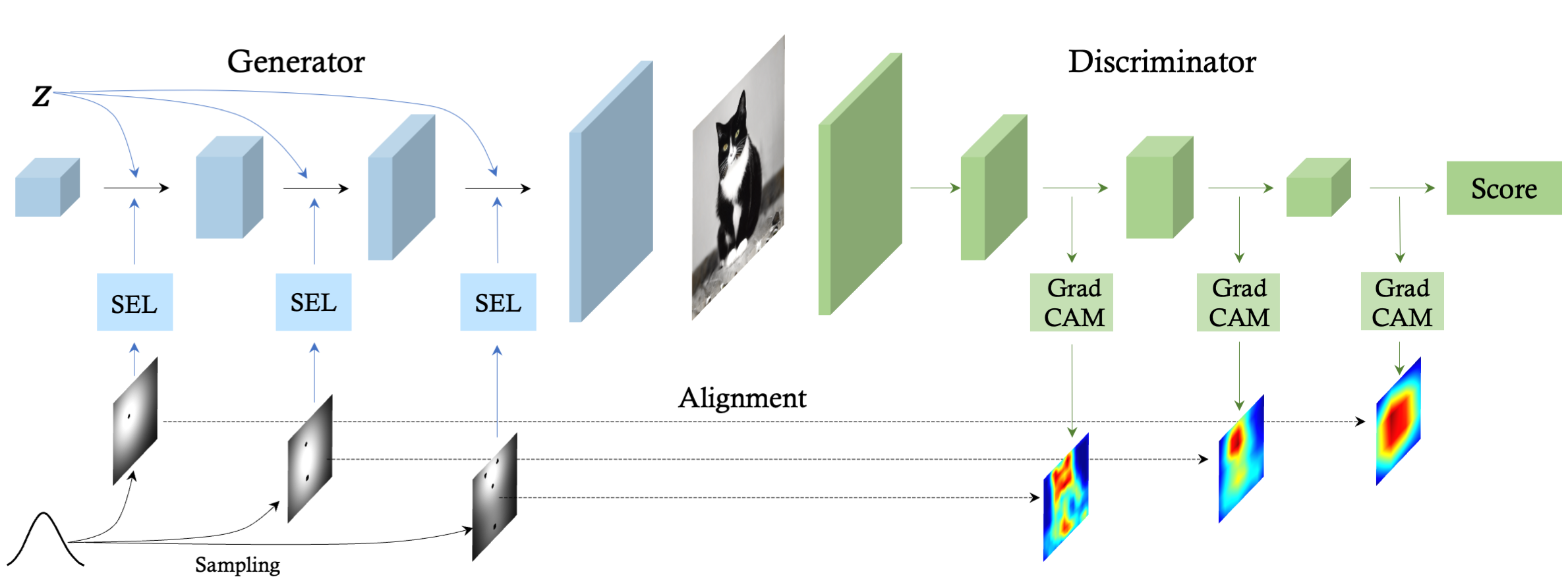
Improving GAN Equilibrium by Raising Spatial Awareness,
|
|
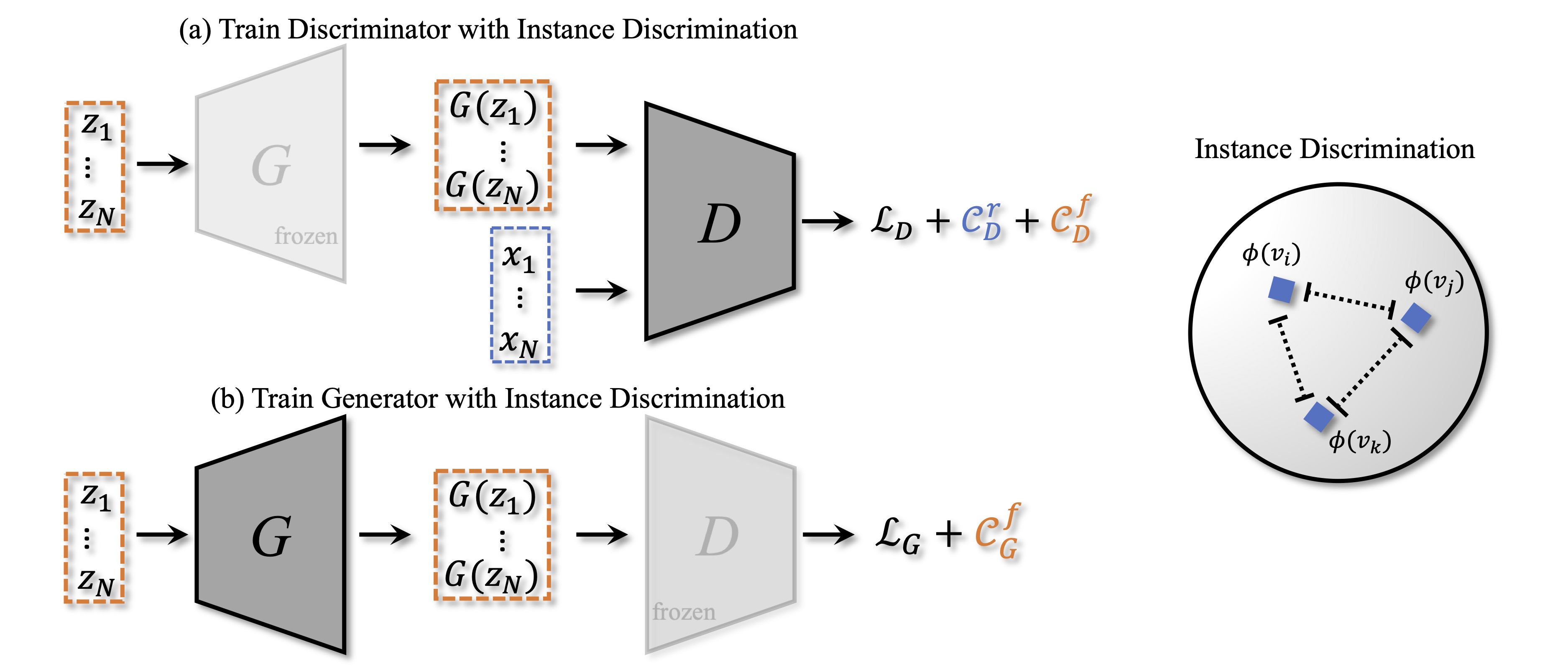
Data-Efficient Instance Generation from Instance Discrimination,
|
|
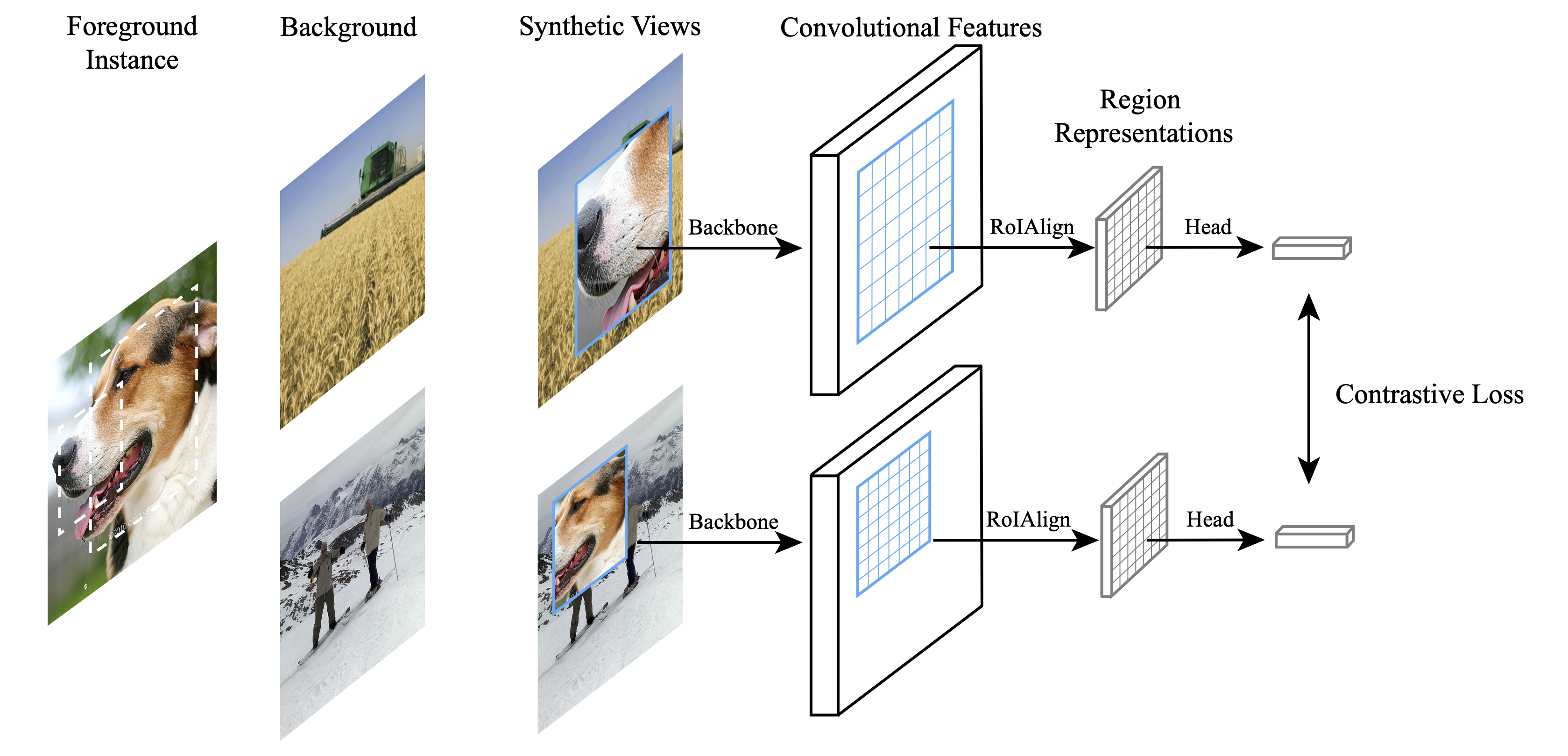
Instance Localization for Self-supervised Detection Pretraining,
|
|
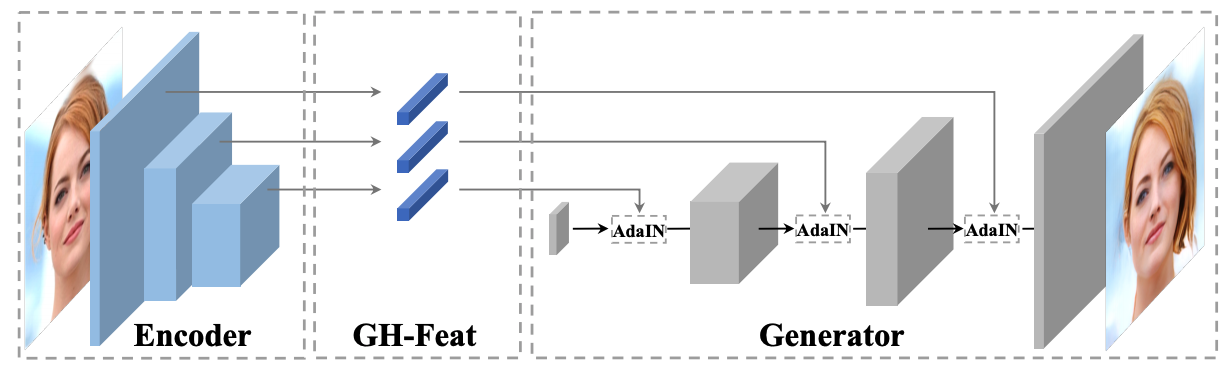
Generative Hierarchical Features from Synthesizing Images,
Oral Presentation
|
|
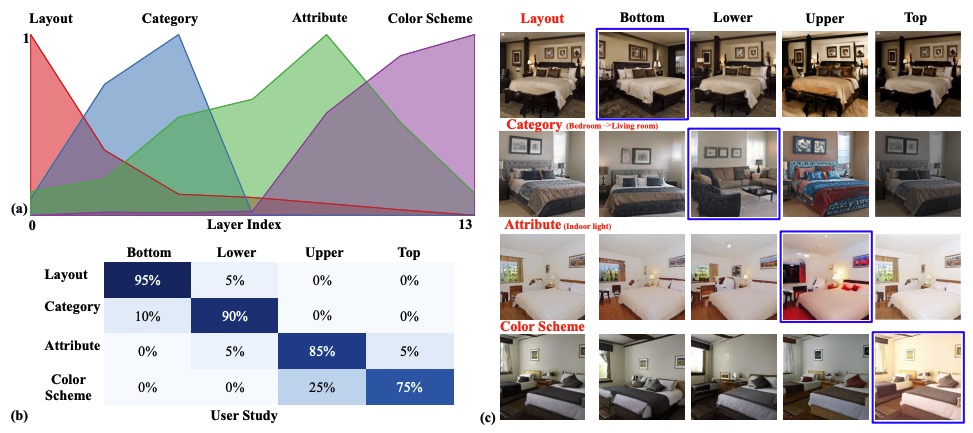
Semantic Hierarchy Emerges in Deep Generative Representations for Scene Synthesis,
|

|
InterFaceGAN: Interpreting the Disentangled Face Representation Learned by GANs,
|
|
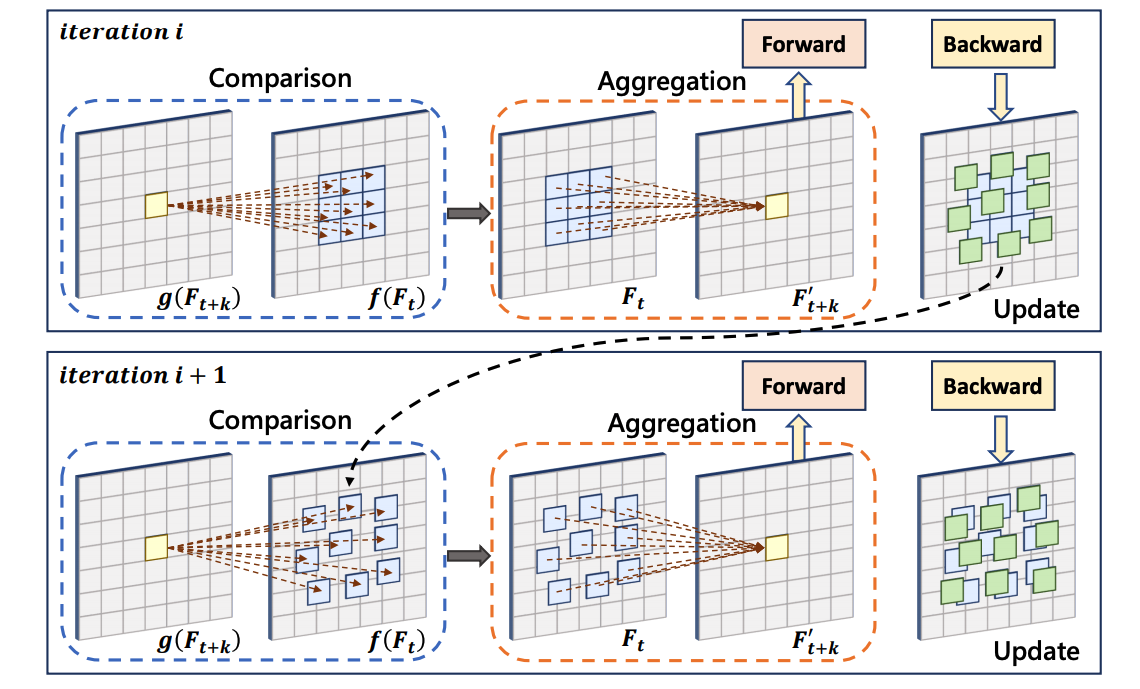
Learning Motion Priors for Efficient Video Object Detection,
|
|
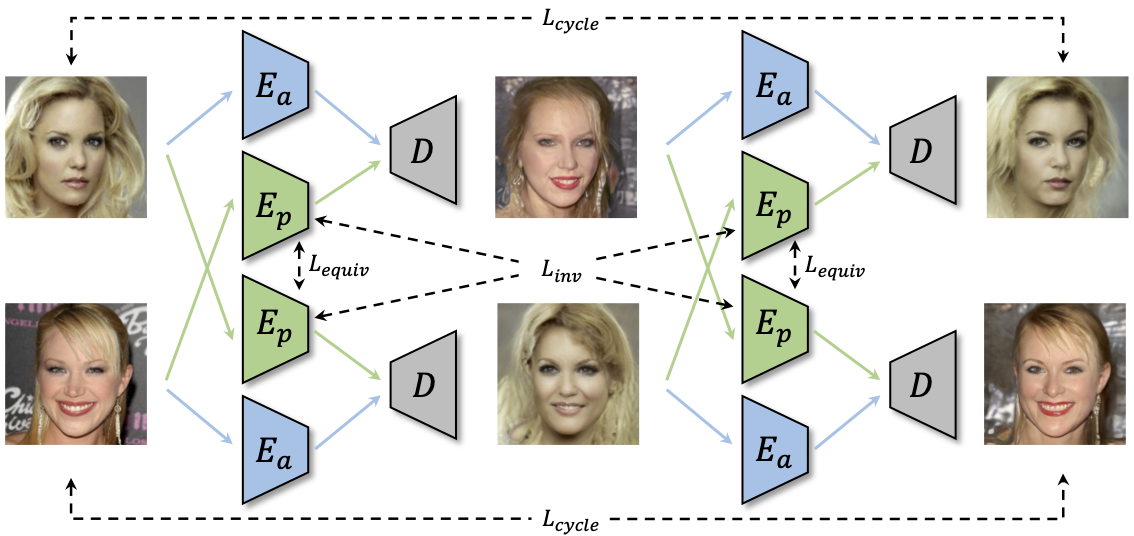
Unsupervised Landmark Learning from Unpaired Data,
|
|
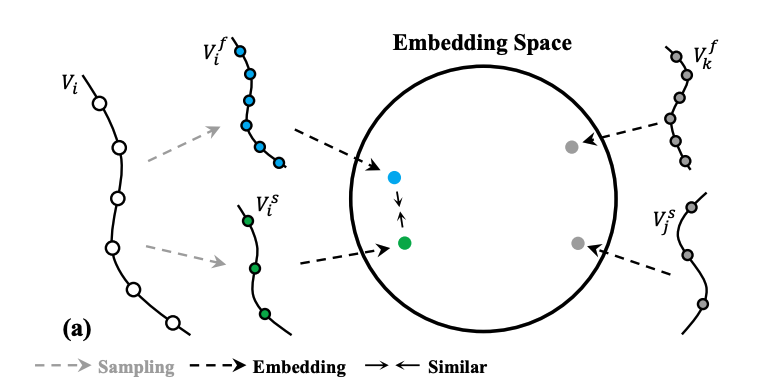
Video Representation Learning with Visual Tempo Consistency,
|
|
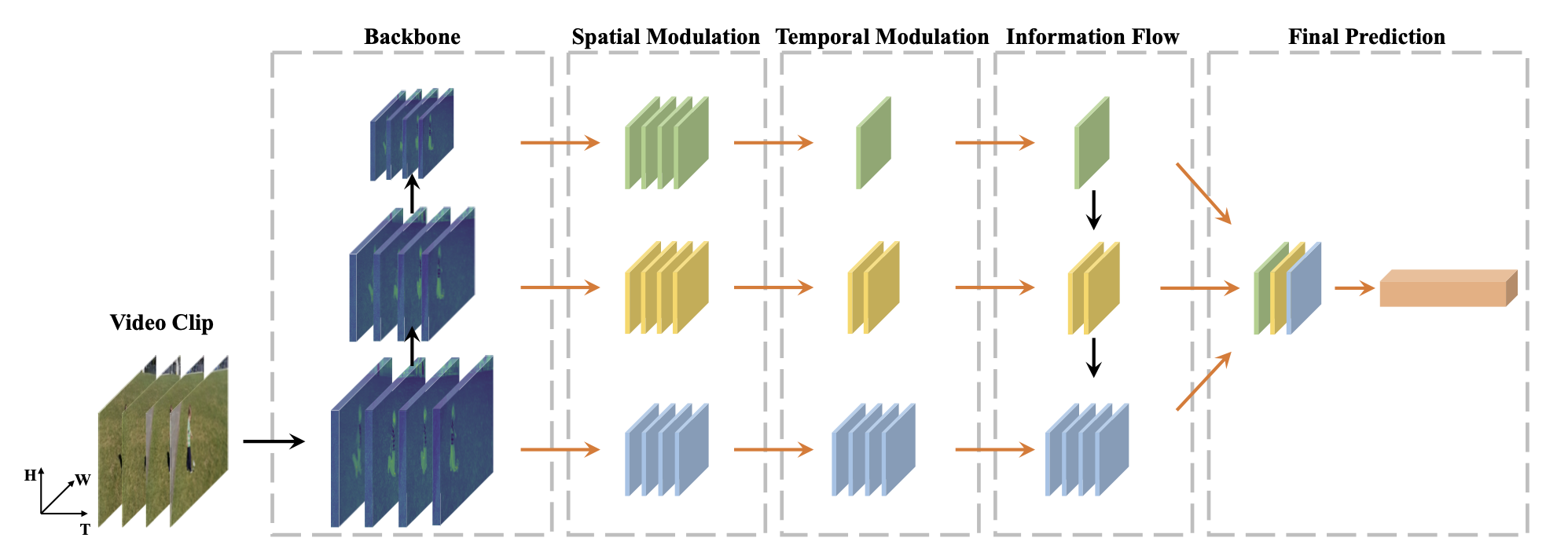
Temporal Pyramid Network for Action Recognition,
|
|
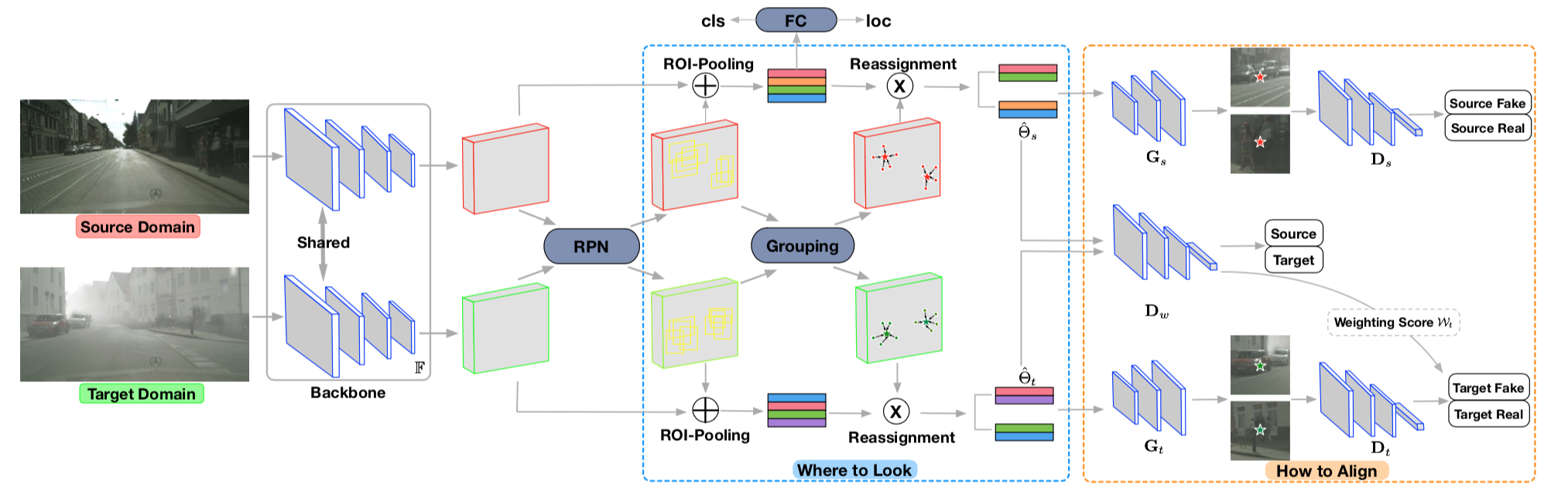
Adapting Object Detectors via Selective Cross-Domain Alignment,
|
|
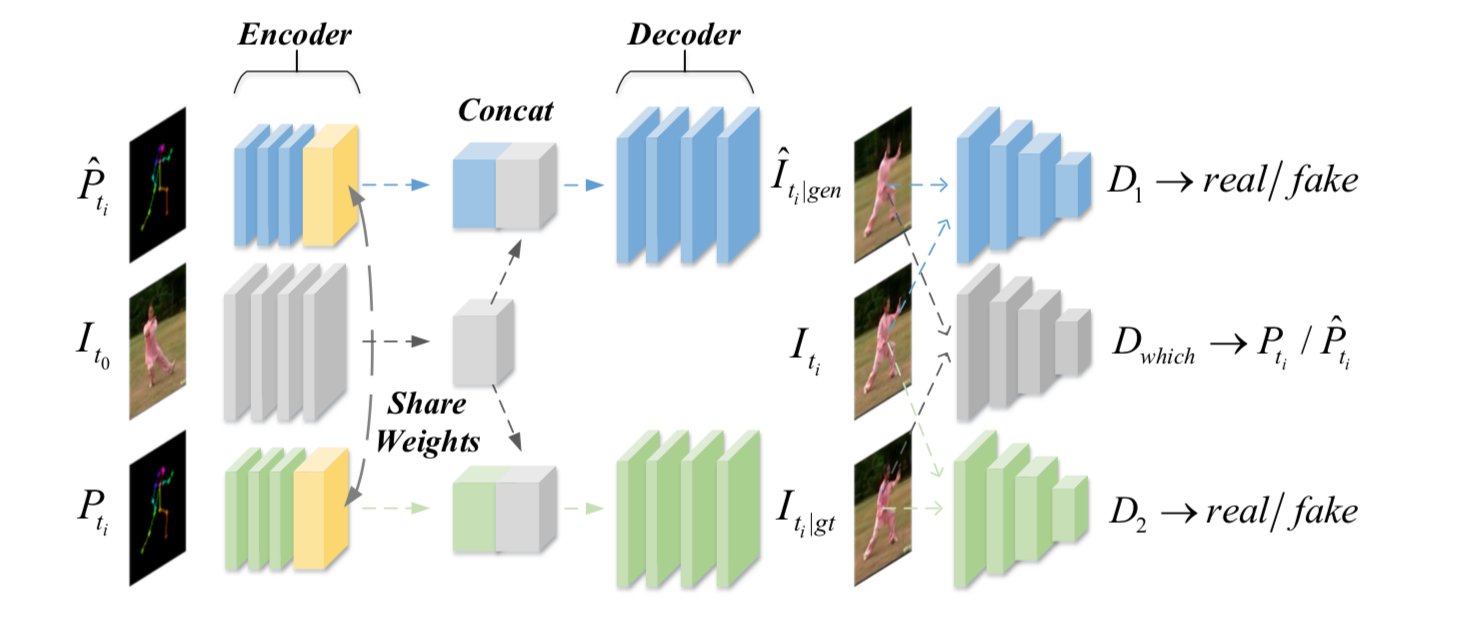
Pose Guided Human Video Generation,
|
|
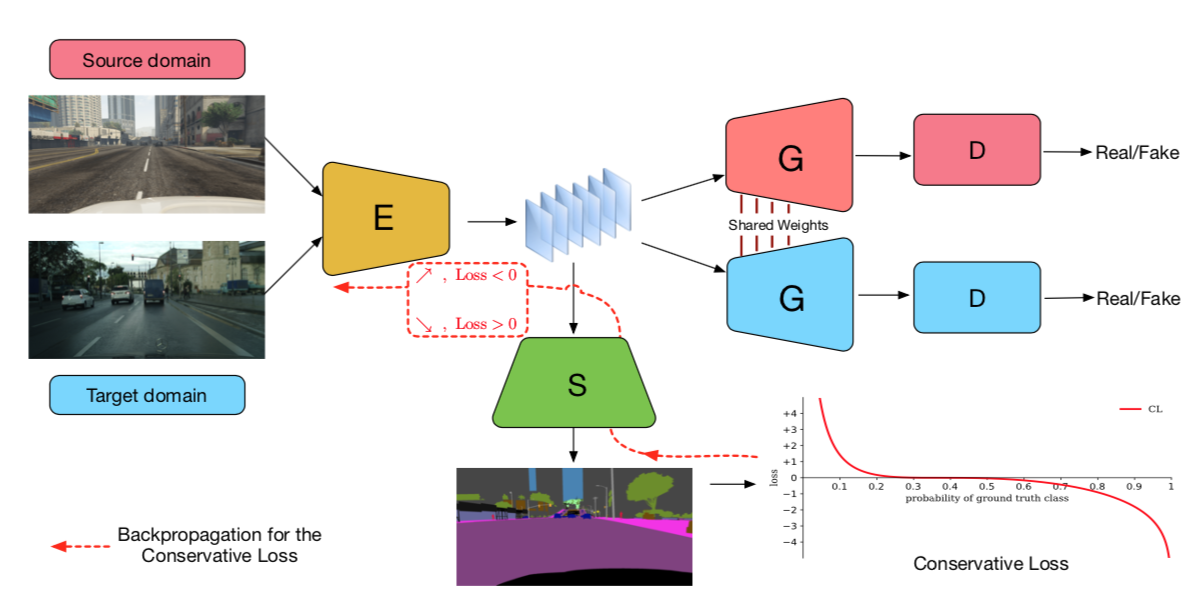
Penalizing Top Performers: Conservative Loss for Semantic Segmentation Adaptation,
|
|
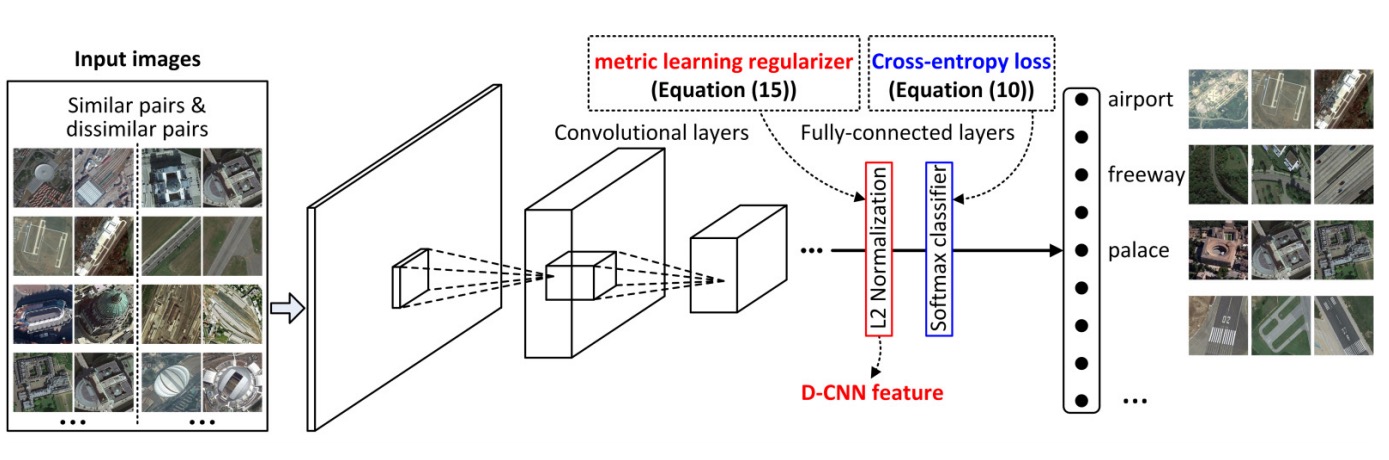
Remote Sensing Image Scene Classification via Learning Discriminative CNNs,
|